Bei meinem Kunden haben wir einige Schleifen mit Metriken und Alerts hinter uns. Die ersten Metriken und Alerts haben am Anfang dazu geführt, dass die Anwendung nur noch mit hohem manuellen Aufwand betreibbar war, da man quasi den einen wichtigen Alert in dem Haufen von anderen ggf. unwichtigeren Alerts nicht gefunden hat. Die Erfahrung und unsere aktuelle Lösung möchte ich hier gerne weitergeben.
Kontext
Der Service, den wir betreiben (die Datendrehscheibe), bettet sich vereinfacht wie folgt in die Systemlandschaft ein:
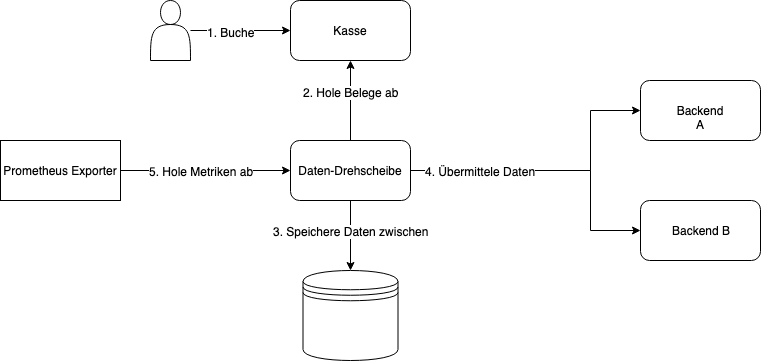
Wir haben Kunden, die an einer Kasse Buchungen vornehmen (1). Danach holt unsere Daten-Drehscheibe Daten von den Kassen ab (2) und speichert diese zwischen (3). Dann werden diese Daten an andere Backends verteilt (4). Als letztes holt dann ein Service die Metriken der Daten-Drehscheibe ab und sendet diese nach Prometheus (5), einer Time Series Datenbank über die wir Metriken und Alerts bei uns realisieren.
1. Wurf: Unbetreibbare Metriken und Alerts
Da es sehr viele Kassen im Einsatz gibt, muss diese Daten-Drehscheibe nun einiges an Durchsatz bewältigen. Bei dem Übertragen der Daten kann einiges schief gehen, bspw. könnte ein Backend die Daten ablehnen, da es irgend etwas an dem gekauften Artikel stört. Auch könnte es sein, dass ein Backend kurzzeitig nicht verfügbar ist. In diesem Fall ist es möglich, später erneut zu versuchen, die Daten zu übertragen. Wir wollten hier nun benachrichtigt werden, wenn irgendetwas schief läuft und wir aktiv werden müssten. Da wir Spring Boot einsetzen, bot sich für das Erzeugen der Metriken Micrometer an. Micrometer ist eine Bibliothek, die verschiedene Klassen anbietet, um diverse Metriken vom Typ Counter, Gauges oder Timer im Code zu verwalten. Am Anfang haben wir viele verschiedene Counter eingebaut, in quasi jeder Story stand drin, dass auch der Counter xyz erhöht und ein Alert erzeugt werden müsse. Bei einem nicht übertragbaren Beleg, wurde also bspw. der dazugehörige Counter hochgezählt.
Es hat sich schnell herausgestellt, dass dieses den Service nur sehr schwer betreibbar macht. Grundsätzlich gab es folgende Probleme:
- Jede Erhöhung eines Fehler-Counters führte zu einem Alert. Diese haben unseren Monitoring Slack Channel / Postfach teilweise dermaßen überflutet, dass wir andere Alerts gar nicht mehr wahrgenommen haben. Sie sind quasi als Nadel im Heuhaufen nicht mehr aufgefallen.
- Es gab auch Fehler, die sich von selber geheilt haben. War ein Backend kurzzeitig nicht verfügbar, so wurde ein Fehler Counter erhöht, da die Daten nicht übertragen werden konnten. Wenn ein Entwickler sich diesen Fehler dann später ansehen wollte, hat er dann häufiger festgestellt, dass er sich schon selber repariert hat und er den Fehler somit umsonst recherchiert hat, da die Daten einfach später erneut (und erfolgreich) übertragen wurden.
- Die Vielzahl an Alerts hat dazu geführt, dass sie irgendwann nicht mehr beachtet wurden.
Aktuelle Lösung: Metriken aus Anwendersicht
Auch wenn es erst einmal intuitiv erscheinen mag, diverse Counter hochzuzählen, da sich daraus schon sinnvolle Alerts ableiten lassen werden, so machen wir das nun nicht mehr. Wir überlegen uns nun immer zuerst, was für einen Alert oder Graphen wir benötigen um den Service betreiben zu können. Dann überlegen wir uns, was für Daten (also Metriken) wir dafür benötigen. Dabei versuchen wir die Daten so zu sammeln, dass wir auch erkennen können, dass eine Störung nicht mehr vorliegt.
In unserem konkreten Beispiel bedeutet es, dass wir bspw. eine Gauge verwenden. Eine Gauge stellt eine Füllstandsmetrik an. Diese kann steigen und sinken. Bei uns gibt sie zurück, wie viele der Belege in der Datenbank als erfolgreich übertragen markiert sind, wieviele noch zur Übertragung ausstehen oder als fehlerhaft markiert sind. Ist die Zahl der fehlerhaften Belege größer null, so stellt das einen fehlerhaften Zustand da und es muss jemand aktiv werden. Aktuell wird diese Zahl bei uns prominent auf einem Monitor dargestellt. Ist sie größer null, so beheben wir das Problem und übertragen die Belege erneut, so dass die Zahl wieder null ist. Man könnte auch einen Alert auslösen der automatisch wieder zurückgenommen wird, sobald die Zahl der fehlerhaften Belege in der Datenbank nur noch null beträgt. Wir erhalten nun also nicht mehr bei jedem Erhöhen des Counters einen Alert. Tritt einmal ein Fehler auf, so sehen wir, dass die Zahl statt null nun bspw. 42 beträgt und werden aktiv.
Auch die noch nicht übertragenen Belege erfassen wir als Kennzahl. Diese Zahl sollte immer gegen null streben. Steigt sie an, so wird die Datendrehscheibe ihre Daten nicht los und wir müssen wieder aktiv werden. Sehen wir bspw. das über 1000 Datensätze noch zur Übertragung ausstehen und es immer mehr werden, so werden wir aktiv. Ist das Problem behoben und werden wir die Daten wieder los, sinkt die Zahl wieder ab und strebt gegen null. Vorher wurde für jeden fehlerhaften Datensatz ein Counter hochgezählt und hat zu einer neuen Alert Benachrichtigung geführt. Nun sehen wir gesammelt die Anzahl der Datensätze und die Tendenz, bekommen aber nicht mehr für jeden einzelnen Fehler einen Alert. Wenn die Anzahl der noch nicht übertragenen Datensätzen gegen null strebt, so sehen wir, dass das Problem behoben ist. Dieses war früher nicht erkennbar, die Fehler-Counter kannten nur den Weg nach oben.
Fazit
Das irgendein Slack Channel oder Mail Postfach mit Alerts überschwemmt wird, sollte unbedingt vermieden werden. Stattdessen braucht man eine Übersicht / Dashboard, das einem aufzeigt, ob gerade ein Problem vorliegt. Ist ein Problem vorhanden, sollte es möglichst sofort sichtbar sein. Wenn man sich dann einig ist, wie man an Hand eines Graphen oder einer Zahl ein Problem erkennt, dann fällt dabei ab, was für Daten / Metriken der Service dafür exportieren muss. Metriken auf Vorrat, ohne Einsatzzweck, würde ich auf jeden Fall vermeiden. Vor allem bei selbstheilenden Systemen muss man wissen, wenn sich eine Störung wieder von selbst behoben hat.