Letztes Jahr habe ich den empfehlenswerten Steering Agile Architecture Kurs von Tudor Girba bei it-agile besucht. Der Aha-Effekt in diesem Kurs kam für mich, als es hieß, die gängige Vorgehensweise bei der Softwareentwicklung sei auf dem Stand der Technik von 1939. Damals wurden vier Millionen Fahrkarten unter immensen Kosten von Hand analysiert, um die Weiterentwicklung des Londoner U-Bahn-Systems zu steuern. Heute würde man dieselben Informationen innerhalb von Sekunden von Servern berechnet bekommen. Laut Tudor Girbas These ähnelte die aktuelle Vorgehensweise in der Softwareentwicklung sehr dem Zählen der Fahrscheine 1939. Um die Gemeinsamkeiten und mögliche Gegenmaßnahmen soll es in diesem Blog Beitrag gehen.
Motivation
In meinem aktuellen Projekt haben wir mehrere Self-Contained Systems. Nun arbeite ich gerade an dem ältesten davon. Dieses ist mit der Zeit zu groß geworden. Um an diesem in Zukunft mit mehr Kollegen arbeiten und es flexibler anpassen zu können, haben wir uns entschieden, dieses erneut aufzuteilen.
Es gibt innerhalb des Self-Contained Systems schon mehrere Deployment Artefakte (Project A, Projekt B und Projekt C), die sich aber ein Datenbankschema teilen:
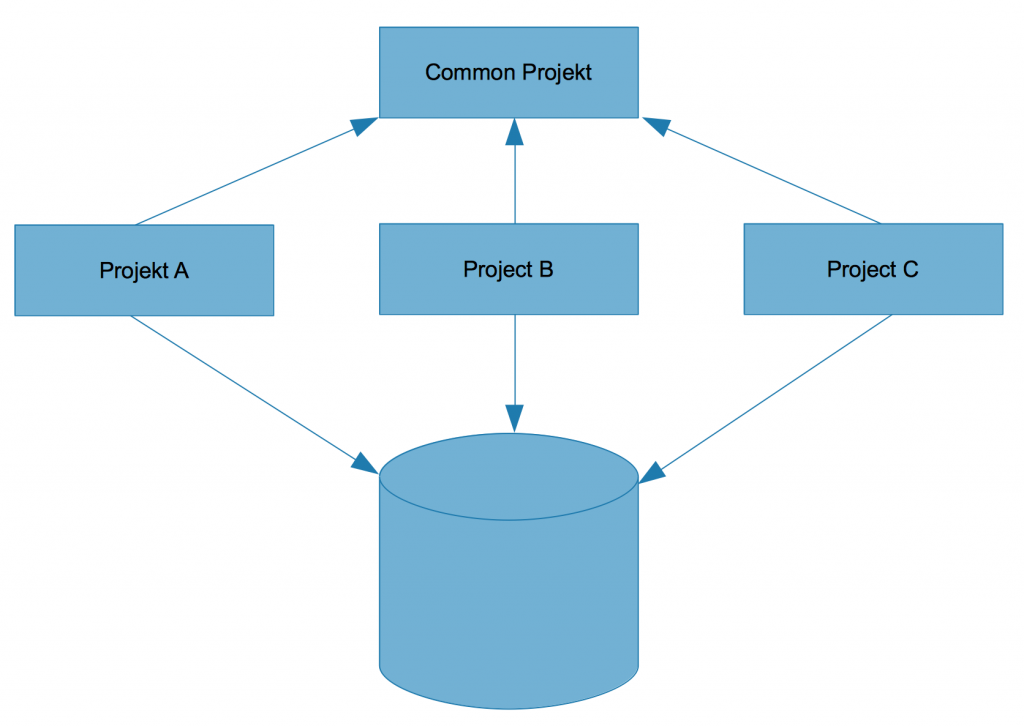
Die Zielvorstellung ist, dass wir irgendwann komplett unabhängige Artefakte haben (also auch mit unabhängigem Datenbankschema). Nun sind die Klassen im common Projekt aber unnötig zusammengewachsen, das Auftrennen der Artefakte ist dadurch nicht so einfach möglich. Um das Trennen vorzubereiten, wollten wir nun das common-Projekt nach und nach aufräumen. Als erstes wollten wir alle Methoden aus dem Common Projekt, die bspw. nur von einem Projekt A benutzt werden (und somit keine Daseinsberechtigung im Common Projekt haben), in das Projekt A verschieben. Die erste Aufgabe, die wir uns gestellt hatten, war also sehr einfach:
Finde alle Methoden in Common, die nur von Projekt A benutzt werden. Danach verschiebe sie nach Projekt A.
Wir sind wie folgt vorgegangen um dieses zu erreichen:
- Klasse für Klasse durchgehen
- Methoden identifizieren, die vermutlich nur von Projekt A verwendet werden
- Verifizieren, dass dieses wirklich so ist
- Methoden evtl. verschieben
Wie man sieht ist dieses sehr ineffizient und dadurch sehr kostenintensiv. Das Suchen nach den Methoden dauert sehr lange und entspricht dem manuellen Analysieren der vier Millionen Tickets der Londoner U-Bahn.
Effizienter wäre stattdessen eine einfache Suche auszuführen und dadurch alle Stellen schnell zu finden, die angepasst werden anpassen. So eine Anfrage könnte wie folgt lauten:
SELECT
m.class, m.methodName
FROM
methods m
WHERE
m.project == ‘Common’ AND setOf(m.callers.project) == (‘Projekt A’)
Weiter könnte durch solch eine Anfrage verhindert werden, dass so eine Methode erneut eingebaut würde. Dazu müsste man bei jedem Build einfach prüfen, dass diese Anfrage nicht mehr Ergebnisse liefert als vorher.
Im Rahmen eines Innovationsevents konnte ich ein paar Kollegen dazu gewinnen an der Umsetzung zu arbeiten. Diese werde ich im Folgenden beschreiben.
Toolauswahl
Tudor Girbas Kurs ist eigentlich Tool-neutral, trotzdem werden dort häufig Beispiele mit seinem Tool Moose gezeigt. Dieses läuft auf einer Pharo Umgebung. Da Pharo eine Smalltalk Implementierung ist, müssen die Anfragen auch in Smalltalk geschrieben werden. Ich habe in der Vergangenheit schon häufiger versucht, meine Projekte mit Moose zu analysieren, habe aber letztendlich immer frustriert auf Grund von Abstürzen oder Performanz-Problemen der Pharo Umgebung abgebrochen.
Ein Kollege hat nun als Alternative das kostenlose Tool jQAssistant vorgeschlagen, das den Binärcode parst und die Daten in eine Neo4j Graph-Datenbank importiert. Da Neo4j auch über eine REST-API verfügt, können auch leicht eigene Visualisierungen bspw. mit d3.js gebaut werden, wenn die native Anzeige von Neo4j nicht ausreichen sollte. Da Neo4j eine populäre Graph-Datenbank mit einer intuitiven Abfragesprache ist, waren wir recht zuversichtlich, dass dieses ausgereifter als Pharo und Moose sein wird. Ein weiterer Pluspunkt war, dass wir wussten, dass auch andere Projekte es schon erfolgreich in den Build Prozess eingebunden haben.
Im Folgenden werde ich also zeigen, wie man mit jQAssistant sehr flexibel seinen Code analysieren kann.
Überblick über jQAssistant
Als Beispielprojekt für die Analyse verwende ich das Spring Projekt. jQAssistant kommt von Haus aus mit einem Kommandozeilenclient sowie einem Maven Plugin. Da wir nur veraltete Gradle Plugins gefunden haben, haben wir uns ein kleines gradle Plugin selber geschrieben dass auch mit der aktuellen jQAssistant Version (aktuell 1.3.0) funktioniert und das die Main Methode von jQAssistant per Java Task aufruft. Zum Ausprobieren reicht aber auch der Kommandozeilen Client. Die folgenden Beispiele werden mit ihm veranschaulicht.
Als einfache Übungsaufgabe wollen wir alle Testmethoden im Spring Projekt finden, die ignoriert werden. Die Query, die Methoden findet, die verschoben werden können, werde ich ganz am Ende zeigen.
Nachdem wir den Client runtergeladen und entpackt haben, können wir ihn mit folgenden Befehlen starten:
#!/bin/sh PROJECT_DIR=./spring-framework/ JQASSISTANT_DIR=./commandline-1.2.0/bin STORE_DIR=./jqassistant_store export JQASSISTANT_OPTS="-Xmx1024M" # In dem Projectverzeichnis suchen wir nach allen classes Verzeichnissen damit wir sie später mit jQAssistant scannen und analysieren können CLASSES_FOLDERS=`find $PROJECT_DIR -iname classes | grep "build/classes" | sed -e "s|\(.*\)|java:classpath::\\1|g" | paste -sd "," -` # Scannen der gefundenen Verzeichnisse. Dabei sorgen wir durch -reset dafür, dass der Store immer neu geschrieben wird $JQASSISTANT_DIR/jqassistant.sh scan -s $STORE_DIR -reset -f $CLASSES_FOLDERS # Nun analysieren wir die Daten. Hier werden bspw. noch weitere Verknüpfungen durch unsere Konzepte erzeugt # Beim Kommdanozeilenclient ist hier wichtig, dass man mindestens das Konzept classpath:Resolve hier verwendet # da ansonsten nur die Klassen usw. innerhalb eines classes Verzeichnis bzw. einer jar miteinander veknüpft sind. # classpath:Resolve stellt diese Verknüpfungen zwischen den jars / classes Verzeichnissen wieder her. # Siehe https://stackoverflow.com/questions/33940842/multiple-jars-with-unique-types $JQASSISTANT_DIR/jqassistant.sh analyze -concepts classpath:Resolve -executeAppliedConcepts -s $STORE_DIR # Nun können wir aus dem Analyseergebnis von vorher noch einen HTML Report erstellen lassen $JQASSISTANT_DIR/jqassistant.sh report -s $STORE_DIR # Starten des Servers $JQASSISTANT_DIR/jqassistant.sh server -s $STORE_DIR
Grundsätzlich muss man verstehen, dass es folgende Phasen gibt:
- Scan
- Analyze
- Report
Diese werden nun im Folgenden beschrieben.
Scan
Scan importiert die Struktur der Anwendung in die Neo4j Datenbank ohne die Daten zu veredeln. Angenommen wir führen (nach dem kompilieren) zuerst folgenden Befehl aus
$JQASSISTANT_DIR/jqassistant.sh scan -s $STORE_DIR -reset -f $CLASSES_FOLDERS
Und starten danach den Server (die Neo4j Datenbank) :
$JQASSISTANT_DIR/jqassistant.sh server -s $STORE_DIR
So sehen wir Folgendes, wenn wir die die Weboberfläche unter http://localhost:7474/ öffnen:
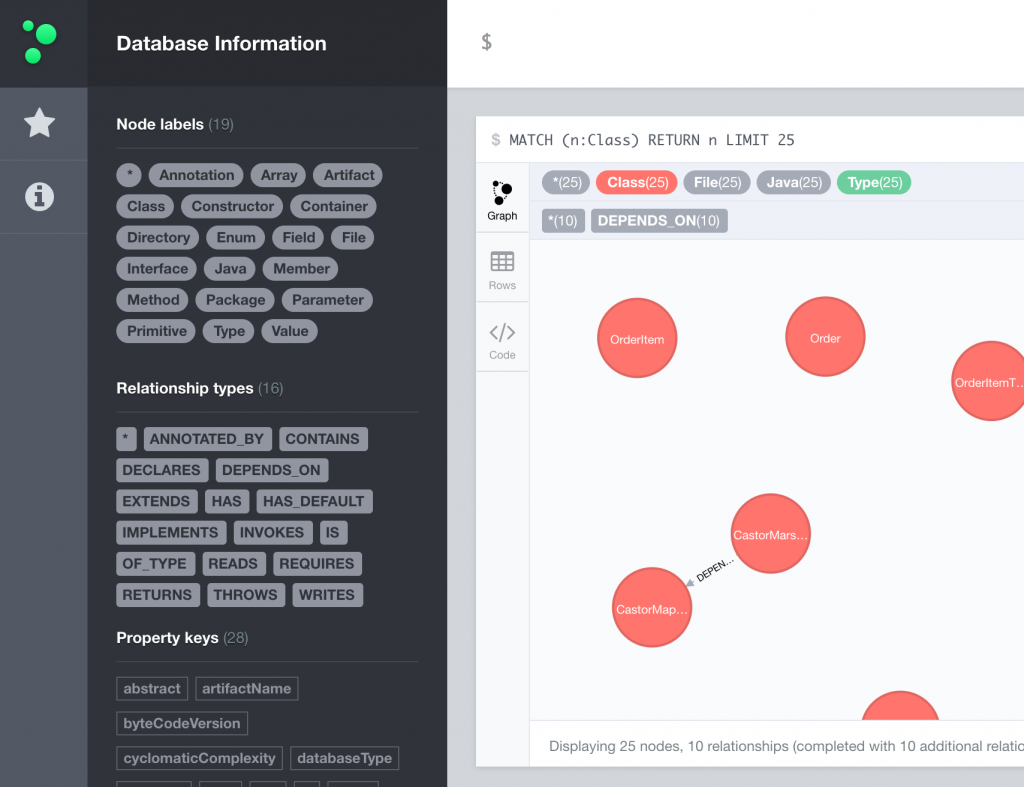
Auf der linken Seite sieht man die vorhandenen Node labels (bspw. Class, Methode, Artifact, …). Auch alle existierenden Relationship types werden hier aufgeführt. Mit diesen kann man nach bestimmten Mustern in der Datenbank suchen. Bspw. nach allen Knoten mit dem Label Class die Beziehung mit dem Label DECLARES zu einem Knoten mit dem Label Method haben. Eine Anfrage MATCH (n:Class) RETURN n LIMIT 25 gibt maximal 25 Knoten mit dem Label Class zurück und zeigt sie an.
Hinweis: Für eine Übersicht über die Syntax von Cypher, der Abfragesprache für Neo4j, siehe folgende Refcard.
Analyze
Jetzt könnte man nach Methoden suchen, die sowohl eine Annotation Ignore als auch Test referenzieren. Dieses ist aber nicht notwendig. In der Analyze Phase kann man nun noch weitere höhere Konzepte anwenden, bspw. könnte man allen Controller Klassen ein Label Controller geben, damit man dieses in späteren Queries verwenden kann. Auch werden in dieser Phase Constraints validiert, die definiert werden können.
Von Haus aus bringt jQAssistant schon einige Konzepte mit, die man hier anwenden kann. Einen Überblick erhält man, indem man den Befehl jqassistant.sh available-rules ausführt. Dieser gibt aus, dass es bspw. folgendes Konzept gibt:
"junit4:IgnoreTestClassOrMethod" - Labels all classes or methods annotated with "@org.junit.Ignore" with "Junit4" and "Ignore".
Da wir als Beispiel alle ignorierten Testmethoden suchen wollen, passt dieses Konzept sehr gut, da es genau diese mit einem Label markiert, so dass man sie einfach finden kann. Dieses Konzept können wir ausführen, indem wir es dem analyze Task übergeben:
$JQASSISTANT_DIR/jqassistant.sh analyze -concepts junit4:IgnoreTestClassOrMethod -executeAppliedConcepts -s $STORE_DIR
Starten wir danach wieder den Server, so sehen wir, dass links nun neue Labels (Ignore, JUnit4, usw.) auftauchen, die von dem Konzept hinzugefügt wurden.
Mit der Query MATCH (m:Ignore:Method) RETURN m können nun alle Tests angezeigt werden, die aktuell im Spring Projekt ignoriert werden (in der Rows Ansicht):
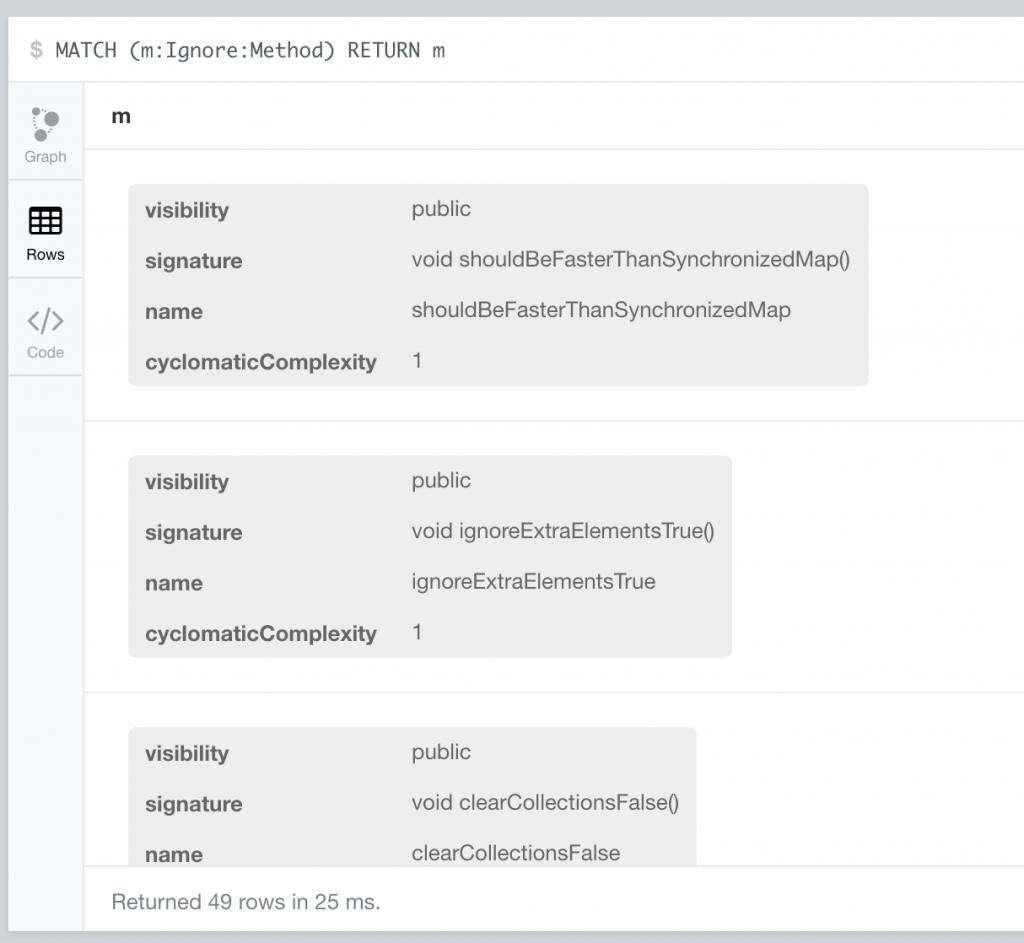
Als Team könnten wir uns nun die Aufgabe setzen, die ignorierten Tests langsam aufzuräumen. Das Ergebnis der Query ist nun dabei unsere Aufgabenliste, die wir abarbeiten wollen. Hierfür reicht uns aber der Methodenname alleine nicht aus. Wir brauchen auch den Namen der Klasse, in dem sich diese Testmethode befindet. Das Datenmodell ist nicht sonderlich gut dokumentiert, dieses ist aber auch nicht nötig. Das liegt daran, dass Neo4j einem schon eine gute Übersicht darüber gibt, was für Labels für Knoten und Beziehungen es gibt.
Auch kann man das Datenmodel am Anfang leicht selber entdecken. Dazu wechseln wir in die Graphen Ansicht (in dem linken Bereich auf den Graph Button klicken):
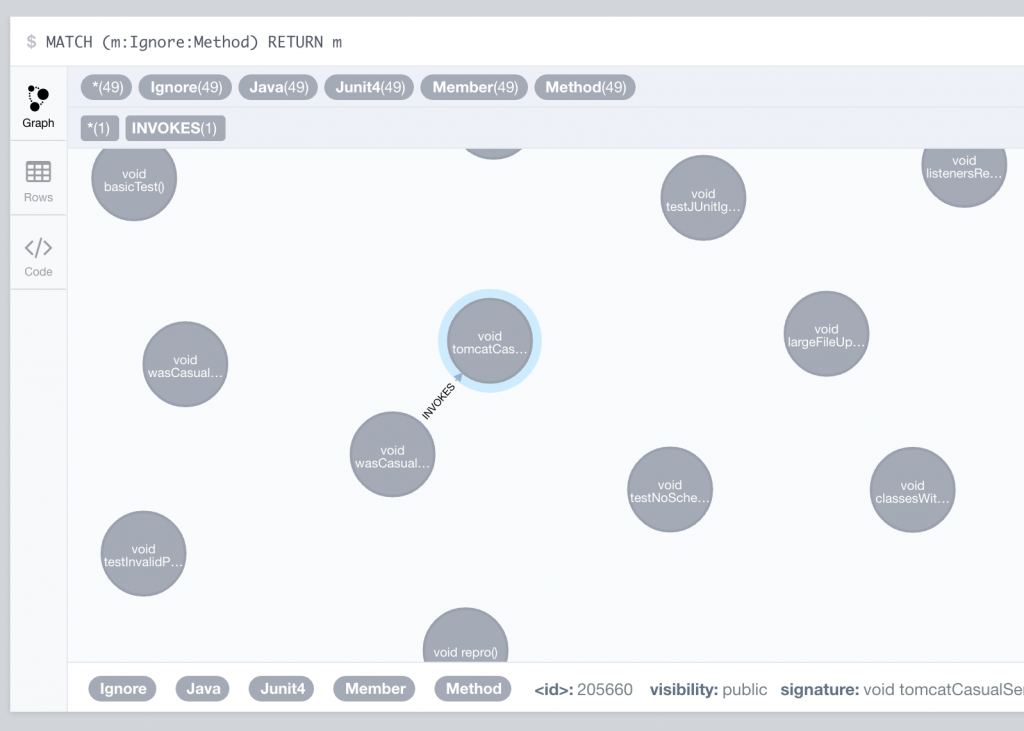
Klickt man hier auf eine Methode doppelt, so bekommt man alle Beziehungen dieses Knotens angezeigt:
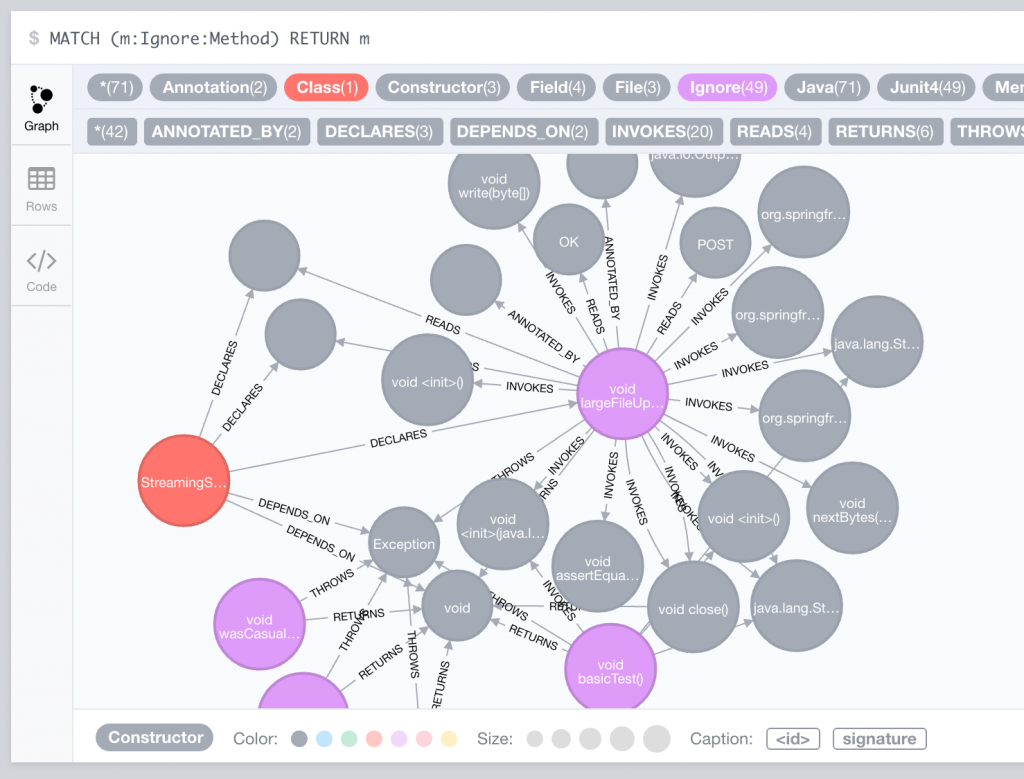
In der obigen Ansicht habe ich mit Neo4j Bordmitteln alle Knoten, die das Label Class haben, rot und alle Knoten, die das Label Ignore haben, lila eingefärbt. Man sieht, dass der rote Knoten (die Klasse) eine direkte Beziehung zu dem lila Knoten (der ignorierten Testmethode) hat und dass der Name dieser Beziehung DECLARES ist. So haben wir also herausbekommen, wie Methoden und Klassen zusammenhängen. Die Query in Cypher (der Abfragesprache für Neo4j) die uns den Namen der Klasse und den Namen der Methode zurückliefert, lautet also folgendermaßen:
MATCH (c:Class)-[:DECLARES]->(m:Ignore:Method) RETURN c.fqn, m.name ORDER BY c.fqn
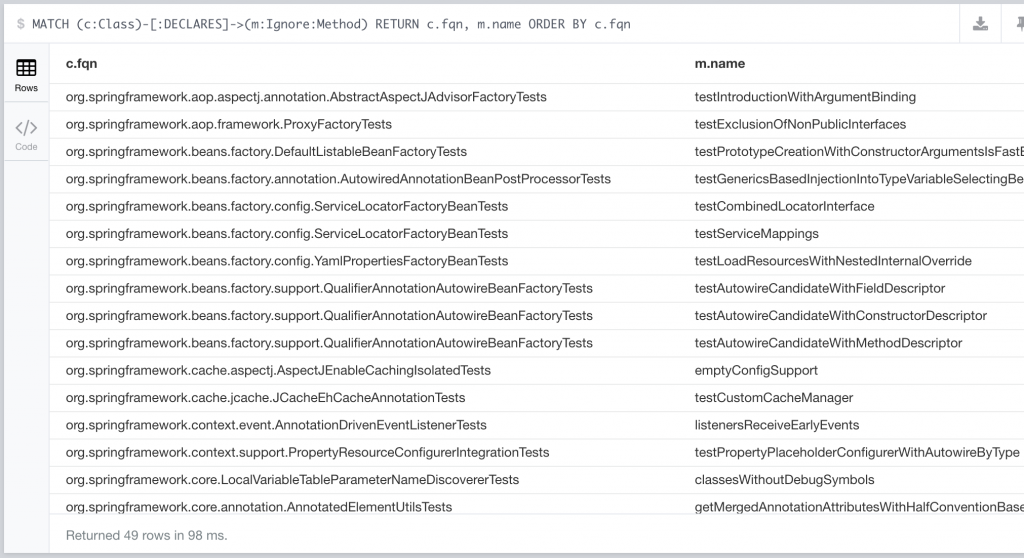
Diese Liste kann man nun schon besser abarbeiten, da sie sowohl den Klassen- als auch den Methodennamen beinhaltet. Nun wollen wir diese Query nicht immer manuell ausführen. Am Besten soll der Build fehlschlagen, wenn ein weiterer Test ignoriert wird. Dafür kann man diese Query nun in eine Constraint verpacken, so dass die Anzahl dieser ignorierten Methoden nicht länger wird und man in einem Report diese Aufgabenliste erhält, die man abarbeiten kann. Dafür legen wir in einem Unterverzeichnis eine xml Datei an und übergeben dieses Verzeichnis per --ruleDirectory Parameter an den analyze Befehl. Diese Datei kann dann folgenden Inhalt haben:
<jqa:jqassistant-rules
xmlns:jqa="http://www.buschmais.com/jqassistant/core/analysis/rules/schema/v1.0">
<constraint id="spring:NoIgnoredTestMethods">
<requiresConcept refId="junit4:IgnoreTestClassOrMethod" />
<description>
We want to clean up our ignored test methods because the test are getting
outdated if they are not executed. So we should delete them or rewrite them.
</description>
<cypher><![CDATA[
MATCH (c:Class)-[:DECLARES]->(m:Ignore:Method) RETURN c.fqn, m.name ORDER BY c.fqn
]]></cypher>
</constraint>
<group id="spring:All">
<includeConcept refId="classpath:Resolve"/>
<!-- Hier stehen noch viele weitere Konzepte und Constraints -->
<includeConstraint refId="spring:NoIgnoredTestMethods"/>
</group>
</jqa:jqassistant-rules>
Eine Constraint oder ein Konzept kann dabei wieder andere Konzepte referenzieren. So drückt unsere Constraint durch <requiresConcept refId="junit4:IgnoreTestClassOrMethod" /> aus, dass das Konzept junit4:IgnoreTestClassOrMethod ausgeführt werden soll, welches die ignorierten Methoden markiert und das wir vorher noch per Hand ausgeführt haben. Auch beinhaltet die Constraint die Query, die wir vorher zusammengebaut haben und die uns die Liste der Namen der ignorierten Tests inkl. deren Klassennamen zurückgibt. Die Vorgehensweise ist, dass man sich in Neo4j zunächst die Query zusammenbaut und diese dann in eine Constraint überführt.
Nun können wir erneut analyze ausführen, was fehlschlägt, da diese Constraint verletzt wird:
RULE_DIR=./spring-rules
$JQASSISTANT_DIR/jqassistant.sh analyze -groups spring:All --ruleDirectory $RULE_DIR -executeAppliedConcepts -s $STORE_DIR$JQASSISTANT_DIR/jqassistant.sh analyze -groups spring:All --ruleDirectory ./spring-rules -executeAppliedConcepts -s $STORE_DIR
In dem obigen Analyze Befehl übergeben wir nun kein Konzept mehr sondern eine Gruppe. Diese kann mehrere Constraints und Konzepte bündeln. Nachdem wir den Analyze Task ausgeführt haben, sehen wir, dass die Constraint fehlgeschlagen ist, da wir noch Ignorierte Testmetoden im Code haben:
Opening store in directory '/Users/meinert/Develop/jqassistant/./jqassistant_store' Executing analysis. Reading rules from directory /Users/meinert/Develop/jqassistant/./spring-rules Executing group 'spring:All' Applying concept 'junit4:IgnoreTestClassOrMethod' with severity: 'MINOR'. Validating constraint 'spring:NoIgnoredTestMethods' with severity: 'INFO'. Verifying results, severity=CRITICAL Constraint failed: spring:NoIgnoredTestMethods, Severity: INFO
Bei einem nicht konstruierten Beispiel würde man diese 25 Verletzungen nun einfach beheben. In der echten Welt könnten hier aber auch hunderte von Verletzungen stehen. In diesem Fall ist es schlecht, dauernd einen fehlgeschlagenen Build zu haben. Es ist besser, wenn der Build erfolgreich ist, solange der Zustand nicht verschlechtert wird. Behebt man dann einige Stellen, so reduziert man die maximale Anzahl der Zeilen (also die Anzahl der Verletzungen), die die Query der Constraint zurückliefern darf. So kann man sicherstellen, dass man sich auf das Ziel zubewegt. Da die Query bei uns aktuell 49 Zeilen zurückliefert, stellen wir also 49 ein:
<constraint id="spring:NoIgnoredTestMethods">
<requiresConcept refId="junit4:IgnoreTestClassOrMethod" />
<description>
We want to clean up our ignored test methods because the test are so old that they won't work anymore. So we should
delete them or rewrite them
</description>
<cypher><![CDATA[
MATCH (c:Class)-[:DECLARES]->(m:Ignore:Method) RETURN c.fqn, m.name ORDER BY c.fqn
]]></cypher>
<verify>
<rowCount max="49"/>
</verify>
</constraint>
Führt man nun ein Analyze durch, so schlägt es nicht fehl. Wird eine weitere Testmethode ignoriert, so schlägt der Task wieder fehl. Würde ein Ignore bei einer Testmethode entfernt werden, so könnten wir die Grenze runtersetzen, so dass wir immer besser werden.
Report
Die Analyse erstellt eine XML Datei. Will man sich das Ergebnis im Browser anzeigen lassen, bspw. um die Aufgabenliste abzuarbeiten, so kann über den Report Task eine HTML Datei aus der XML Datei erzeugt werden.
$JQASSISTANT_DIR/jqassistant.sh report -s $STORE_DIR
Das Ergebnis kann man sich dann im Browser ansehen:
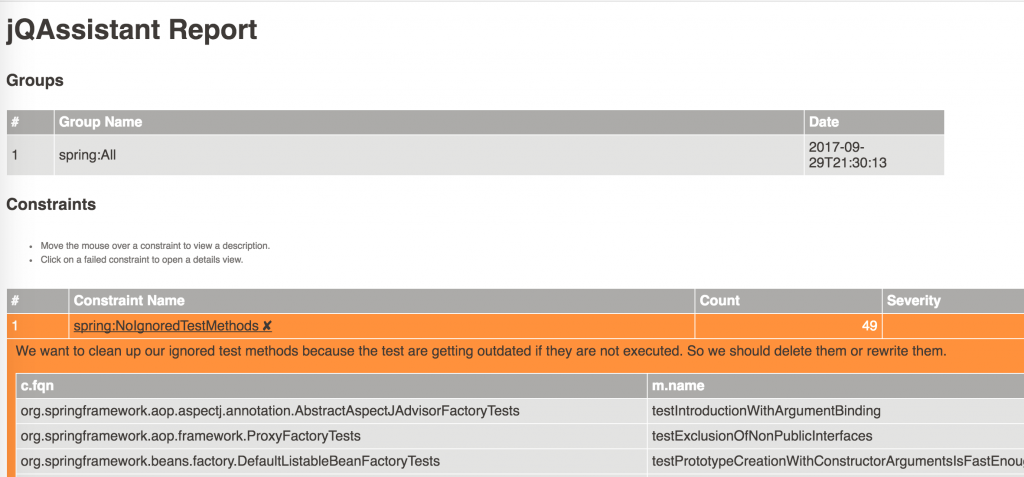
Eine kompliziertere Query
Die Query zum Finden der ignorierten Testmethoden war noch recht einfach. Hier werden wahrscheinlich auch einige sagen, dass man dieses noch über eine einfache Checkstyle Regel hätte erledigen können. Der große Vorteil von jQAssistant ist aber die große Flexibilität. Mit folgender Query können bspw. die Methoden aus dem gemeinsam verwendeten Projekt project-common gefunden werden, die nur von einem anderem Projekt verwendet werden und demzufolge in dieses Projekt verschoben werden können. So eine Query ist zu projektspezifisch, als dass sie mit Checkstyle oder einem anderen Tool, das Standard-Checks überprüft, gefunden werden könnte:
MATCH (ta:Artifact)-->(tc:Class)-[:DECLARES]->(tm:Method) <-[:INVOKES]-(:Method)<-[:DECLARES]-(:Class) <--(ca:Artifact) WITH ta, tc, tm , collect(distinct ca.artifactName) as callers WHERE ta.artifactName = 'project-common' AND size(callers) = 1 AND NOT 'project-common' in callers RETURN tc.name, tm.signature, callers ORDER BY tc.name
Dabei bedeutet folgende MATCH Clause:
MATCH (ta:Artifact)-->(tc:Class)-[:DECLARES]->(tm:Method) <-[:INVOKES]-(:Method)<-[:DECLARES]-(:Class) <--(ca:Artifact)
dass wir ein Artifakt suchen, das eine Klasse referenziert, die eine Methode deklariert, die von einer anderen Methode aufgerufen wird, die in einer Klasse deklariert ist, die in einem Artifakt liegt.
Mit folgender WITH Clause
WITH ta, tc, tm , collect(distinct ca.artifactName) as callers
sammeln wir dann das aufgerufene Artifakt sowie die aufgerufene Methode und Klasse zusammen. Auch sammeln wir über collect(distinct ca.artifactName) die Namen aller Artefakte zusammen, aus denen heraus die Methode aufgerufen wird.
Mit der WHERE Clause
WHERE ta.artifactName = 'project-common' AND size(callers) = 1 AND NOT 'project-common' in callers
finden wir dann alle Einträge, die nur von einem Projekt aus aufgerufen werden. Dabei ignorieren wir alle Methoden, die nur aus dem common Projekt aufgerufen werden.
Dieses sieht dann als Konzept und Constraint wie folgt aus:
<concept id="poc:ArtifactName">
<description>The artifacts should have a field artifactName
</description>
<cypher><![CDATA[
MATCH (n:Artifact)
WITH n, (filter( part in split(n.fileName, '/') where part contains 'project-')[0]) as artifactName
SET n.artifactName = artifactName
RETURN n, artifactName
]]></cypher>
</concept>
<constraint id="poc:CommonMethodsWhichCouldBeUsed" severity="minor">
<requiresConcept refId="airfreight:ArtifactName"/>
<description>We want to finde artifacts which can be moved out of common because they are only used by one artifact
</description>
<cypher><![CDATA[
MATCH
(ta:Artifact)-[:CONTAINS]->(tc:Class)-[:DECLARES]->(tm:Method)<-[:INVOKES]-(:Method)<-[:DECLARES]-(:Class)<-[:CONTAINS]-(ca:Artifact)
WITH
tm, tc, ta, collect(distinct ca.artifactName) as callers
SET tm:MethodWhichCanBeMoved, tc:ClassWithMethodsWhichCanBeMoved
WHERE
ta.artifactName = 'project-common'
AND size(callers) = 1
and not 'project-common' in callers
RETURN
tc.fqn,tm.signature, callers
order by tc.fqn
]]></cypher>
</constraint>
Hier haben wir noch eine kleine Ergänzung hinzugefügt. Über die SET Clause markieren wir die gefundenen Klassen und Methoden mit einem Label (MethodWhichCanBeMoved und ClassWithMethodsWhichCanBeMoved), so dass wir sie einfacher finden und auch im Neo4j Browser farblich markieren können:
SET tm:MethodWhichCanBeMoved, tc:ClassWithMethodsWhichCanBeMoved
Das Konzept poc:ArtifactName ist dazu da, um den Projektnamen an das Artifakt-Knoten zu schreiben. Standardmäßig hat dieser nur ein Attribute das den kompletten Pfad enthält. Die Constraint poc:CommonMethodsWhichCouldBeUsed gibt nun bei einem Build die Liste der Methoden aus, die wir in die jeweiligen Projekte verschieben können. Natürlich sind da trotzdem noch einige Methoden dabei, die man lieber in dem common Projekt lassen will. Vorher sind wir die Projekte aber von Hand durchgegangen um solche Stellen zu finden. Nun haben wir aber schon eine recht kurze vorgefilterte Liste, die wir überprüfen können. Auch können wir diese Liste von Methoden noch graphisch aufbereiten, um die Methoden, die wir verschieben wollen, leichter zu identifizieren. Weiter können wir uns auch erst einmal auf Methoden in Klassen mit bestimmten Muster beschränken, bspw. auf alle Services. Das Schreiben dieser Query hat mich weniger 10 Minuten gedauert. Das ist eine immense Zeitersparnis verglichen mit dem manuellen Durchsuchen des Codes.
Anmerkungen:
- Scannt man mehrere Verzeichnisse oder jar Dateien mit jQAssistant per Kommandozeile, so gibt es keine Verbindungen zwischen den Knoten dieser Artefakte. Wird also eine Klasse aus common in project-a verwendet, gibt es zwei Knoten für diese Klasse, ohne dass diese miteinander verbunden sind. Durch Anwenden des Konzeptes
classpath:Resolvekönnen diese Knoten aber wieder miteinander verbunden werden. Die Gründe warum dieses per Default so ist, sind hier beschrieben. Hat man ein Multi Module Maven Projekt und verwendet das Maven Plugin, so soll das allerdings nicht notwendig sein. - Wir haben in der Firma ein gradle Plugin geschrieben. Dieses lässt sich gut in den Build einfügen. Gradle ist verglichen mit dem Kommandozeilen Client aber ziemlich langsam. Ich würde also unter Umständen, um nicht so lange warten zu müssen, zusätzlich zum Gradle Plugin auch noch den Kommandozeilen Client einsetzen. Wie performant das Maven Plugin ist weiß ich nicht, da wir in meiner Abteilung aktuell nur Gradle Projekte haben.
- Mit d3.js kann man sich Graphen zeichnen lassen. Es gibt hierzu auch Anleitungen, wie man d3.js mit Neo4j verwendet. Allerdings ist das schon recht aufwändig. Für mich reichte bisher meistens die reine Listenansicht sowie der hauseigene Neo4j Browser. Vor allem, da man in diesem für Labels Farben vergeben kann.
- Interessant ist auch die Möglichkeit, jQAssistant in AsciiDoc zu integrieren. Hiermit haben wir bisher aber noch keine Erfahrungen gemacht.
Fazit
Ich kann nur jedem empfehlen jQAssistant einzusetzen. Es ist sehr einfach zu erlernen. Dieses liegt daran, dass es die Daten in Neo4j importiert und dafür die Dokumentation sehr gut ist. Auch eignet sich die Cypher Abfragesprache sehr gut, um sehr komplexe Muster im Code zu suchen. Auch jQAssistant ist auf der dazugehörigen Seite gut dokumentiert – und was dort nicht dokumentiert ist findet man auf Stackoverflow.
Mir gefällt, dass man durch die Neo4j Datenbank nicht so eingeschränkt ist. So könnte man, wenn man wollte, noch weitere Knoten und Beziehungen hinzufügen. Hätte man bspw. mehrere Mikroservices, so könnte man diese alle in die Neo4j Datenbank importieren und dann (bspw. über Logs oder über dem Auswerten von Annotationen) in der Neo4j Datenbank wieder verbinden, so dass man das System ganzheitlich betrachten kann. Dieses können Standardtools nicht leisten, da die Art diese Verbindung herzustellen, sehr spezifisch ist.
Weiter gefällt mir, dass wir hierdurch selbst die komplexesten Abfragen flexibel und schnell zusammenstellen können. Regeln die wir uns als Team überlegen, können durch jQAssistant schnell in den Buildprozess integriert werden (bspw. keine ignorierten Tests, keine Optionals als Parameter in Methoden usw.) so dass diese dokumentiert sind und auch nicht verletzt werden können.
Standardtools wie Checkstyle, PMD oder Degraph würde ich mit jQAssistant allerdings nicht ersetzen. Warum sollte man deren Checks in jQAssistant auch nachbauen? Aber alle anderen projektspezifischen Checks, die es nicht schon vordefiniert in einem dieser Tools gibt, würde ich in jQAssistant erstellen, da es in in jQAssistant sehr einfach und sehr flexibel möglich ist dieses zu tun.
Ich bin nun sehr begeistert. Bei uns haben wir jQAssistant in den Buildprozess integriert. Nun haben wir endlich ein Tool in der Hand, mit dem wir kleine Regeln und auch größere Architektur Refactorings sicher steuern können, da das Bauen dieser Queries und Constraints sehr schnell geht. Das händische langsame durchsuchen des Codes nach bestimmten Mustern gehört nun endlich der Vergangenheit an.